 Deutsch
Deutsch%22%2F%3E%20%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M0%2039.4h972.8v39.4H0zm0%2078.8h972.8v39.3H0zm0%2078.7h972.8v39.4H0zm0%2078.8h972.8v39.4H0zm0%2078.8h972.8v39.4H0zm0%2078.7h972.8v39.4H0z%22%20transform%3D%22scale(.9375)%22%2F%3E%20%3C%2Fg%3E%20%3Cpath%20fill%3D%22%23192f5d%22%20d%3D%22M0%200h389.1v275.7H0z%22%20transform%3D%22scale(.9375)%22%2F%3E%20%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M32.4%2011.8L36%2022.7h11.4l-9.2%206.7%203.5%2011-9.3-6.8-9.2%206.7%203.5-10.9-9.3-6.7H29zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.5%2011-9.2-6.8-9.3%206.7%203.5-10.9-9.2-6.7h11.4zm64.8%200l3.6%2010.9H177l-9.2%206.7%203.5%2011-9.3-6.8-9.2%206.7%203.5-10.9-9.3-6.7h11.5zm64.9%200l3.5%2010.9H242l-9.3%206.7%203.6%2011-9.3-6.8-9.3%206.7%203.6-10.9-9.3-6.7h11.4zm64.8%200l3.6%2010.9h11.4l-9.2%206.7%203.5%2011-9.3-6.8-9.2%206.7%203.5-10.9-9.2-6.7h11.4zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.6%2011-9.3-6.8-9.3%206.7%203.6-10.9-9.3-6.7h11.5zM64.9%2039.4l3.5%2010.9h11.5L70.6%2057%2074%2067.9l-9-6.7-9.3%206.7L59%2057l-9-6.7h11.4zm64.8%200l3.6%2010.9h11.4l-9.3%206.7%203.6%2010.9-9.3-6.7-9.3%206.7L124%2057l-9.3-6.7h11.5zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.5%2010.9-9.2-6.7-9.3%206.7%203.5-10.9-9.2-6.7H191zm64.8%200l3.6%2010.9h11.4l-9.3%206.7%203.6%2010.9-9.3-6.7-9.2%206.7%203.5-10.9-9.3-6.7H256zm64.9%200l3.5%2010.9h11.5L330%2057l3.5%2010.9-9.2-6.7-9.3%206.7%203.5-10.9-9.2-6.7h11.4zM32.4%2066.9L36%2078h11.4l-9.2%206.7%203.5%2010.9-9.3-6.8-9.2%206.8%203.5-11-9.3-6.7H29zm64.9%200l3.5%2011h11.5l-9.3%206.7%203.5%2010.9-9.2-6.8-9.3%206.8%203.5-11-9.2-6.7h11.4zm64.8%200l3.6%2011H177l-9.2%206.7%203.5%2010.9-9.3-6.8-9.2%206.8%203.5-11-9.3-6.7h11.5zm64.9%200l3.5%2011H242l-9.3%206.7%203.6%2010.9-9.3-6.8-9.3%206.8%203.6-11-9.3-6.7h11.4zm64.8%200l3.6%2011h11.4l-9.2%206.7%203.5%2010.9-9.3-6.8-9.2%206.8%203.5-11-9.2-6.7h11.4zm64.9%200l3.5%2011h11.5l-9.3%206.7%203.6%2010.9-9.3-6.8-9.3%206.8%203.6-11-9.3-6.7h11.5zM64.9%2094.5l3.5%2010.9h11.5l-9.3%206.7%203.5%2011-9.2-6.8-9.3%206.7%203.5-10.9-9.2-6.7h11.4zm64.8%200l3.6%2010.9h11.4l-9.3%206.7%203.6%2011-9.3-6.8-9.3%206.7%203.6-10.9-9.3-6.7h11.5zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.5%2011-9.2-6.8-9.3%206.7%203.5-10.9-9.2-6.7H191zm64.8%200l3.6%2010.9h11.4l-9.2%206.7%203.5%2011-9.3-6.8-9.2%206.7%203.5-10.9-9.3-6.7H256zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.5%2011-9.2-6.8-9.3%206.7%203.5-10.9-9.2-6.7h11.4zM32.4%20122.1L36%20133h11.4l-9.2%206.7%203.5%2011-9.3-6.8-9.2%206.7%203.5-10.9-9.3-6.7H29zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.5%2010.9-9.2-6.7-9.3%206.7%203.5-10.9-9.2-6.7h11.4zm64.8%200l3.6%2010.9H177l-9.2%206.7%203.5%2011-9.3-6.8-9.2%206.7%203.5-10.9-9.3-6.7h11.5zm64.9%200l3.5%2010.9H242l-9.3%206.7%203.6%2011-9.3-6.8-9.3%206.7%203.6-10.9-9.3-6.7h11.4zm64.8%200l3.6%2010.9h11.4l-9.2%206.7%203.5%2011-9.3-6.8-9.2%206.7%203.5-10.9-9.2-6.7h11.4zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.6%2011-9.3-6.8-9.3%206.7%203.6-10.9-9.3-6.7h11.5zM64.9%20149.7l3.5%2010.9h11.5l-9.3%206.7%203.5%2010.9-9.2-6.8-9.3%206.8%203.5-11-9.2-6.7h11.4zm64.8%200l3.6%2010.9h11.4l-9.3%206.7%203.6%2010.9-9.3-6.8-9.3%206.8%203.6-11-9.3-6.7h11.5zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.5%2010.9-9.2-6.8-9.3%206.8%203.5-11-9.2-6.7H191zm64.8%200l3.6%2010.9h11.4l-9.2%206.7%203.5%2010.9-9.3-6.8-9.2%206.8%203.5-11-9.3-6.7H256zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.5%2010.9-9.2-6.8-9.3%206.8%203.5-11-9.2-6.7h11.4zM32.4%20177.2l3.6%2011h11.4l-9.2%206.7%203.5%2010.8-9.3-6.7-9.2%206.7%203.5-10.9-9.3-6.7H29zm64.9%200l3.5%2011h11.5l-9.3%206.7%203.6%2010.8-9.3-6.7-9.3%206.7%203.6-10.9-9.3-6.7h11.4zm64.8%200l3.6%2011H177l-9.2%206.7%203.5%2010.8-9.3-6.7-9.2%206.7%203.5-10.9-9.3-6.7h11.5zm64.9%200l3.5%2011H242l-9.3%206.7%203.6%2010.8-9.3-6.7-9.3%206.7%203.6-10.9-9.3-6.7h11.4zm64.8%200l3.6%2011h11.4l-9.2%206.7%203.5%2010.8-9.3-6.7-9.2%206.7%203.5-10.9-9.2-6.7h11.4zm64.9%200l3.5%2011h11.5l-9.3%206.7%203.6%2010.8-9.3-6.7-9.3%206.7%203.6-10.9-9.3-6.7h11.5zM64.9%20204.8l3.5%2010.9h11.5l-9.3%206.7%203.5%2011-9.2-6.8-9.3%206.7%203.5-10.9-9.2-6.7h11.4zm64.8%200l3.6%2010.9h11.4l-9.3%206.7%203.6%2011-9.3-6.8-9.3%206.7%203.6-10.9-9.3-6.7h11.5zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.5%2011-9.2-6.8-9.3%206.7%203.5-10.9-9.2-6.7H191zm64.8%200l3.6%2010.9h11.4l-9.2%206.7%203.5%2011-9.3-6.8-9.2%206.7%203.5-10.9-9.3-6.7H256zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.5%2011-9.2-6.8-9.3%206.7%203.5-10.9-9.2-6.7h11.4zM32.4%20232.4l3.6%2010.9h11.4l-9.2%206.7%203.5%2010.9-9.3-6.7-9.2%206.7%203.5-11-9.3-6.7H29zm64.9%200l3.5%2010.9h11.5L103%20250l3.6%2010.9-9.3-6.7-9.3%206.7%203.6-11-9.3-6.7h11.4zm64.8%200l3.6%2010.9H177l-9%206.7%203.5%2010.9-9.3-6.7-9.2%206.7%203.5-11-9.3-6.7h11.5zm64.9%200l3.5%2010.9H242l-9.3%206.7%203.6%2010.9-9.3-6.7-9.3%206.7%203.6-11-9.3-6.7h11.4zm64.8%200l3.6%2010.9h11.4l-9.2%206.7%203.5%2010.9-9.3-6.7-9.2%206.7%203.5-11-9.2-6.7h11.4zm64.9%200l3.5%2010.9h11.5l-9.3%206.7%203.6%2010.9-9.3-6.7-9.3%206.7%203.6-11-9.3-6.7h11.5z%22%20transform%3D%22scale(.9375)%22%2F%3E%20%3C%2Fg%3E%20%3C%2Fsvg%3E) English
English Français
Français%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(-12.33562%20-20.5871%2020.58684%20-12.33577%20240.3%2048)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(-3.38573%20-23.75998%2023.75968%20-3.38578%20288%2095.8)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(6.5991%20-23.0749%2023.0746%206.59919%20288%20168)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(14.9991%20-18.73557%2018.73533%2014.99929%20240%20216)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3C%2Fsvg%3E) 简体中文
简体中文Что такое I2P и как он работает | Онлайнсим
- 18 янв. 2023 г., 17:29
- 12 минут
В прошлой части мы рассказывали, что такое Freenet и браузер Tor и что с их помощью можно делать в темном интернете.
В новой статье обсудим, что такое сеть I2P, как она работает и какие задачи решает.
В других статьях серии:
- Тайный интернет, часть 1: что такое Dark Web и зачем его используют
- Тайный интернет, часть 2: как устроены .onion сайты
- Тайный интернет, часть 3: что такое Freenet
- Тайный интернет, часть 4: что такое I2P и как он работает ← вы здесь
- Тайный интернет, часть 5: как попасть в Darkweb через Tor, I2P и Freenet
Что такое I2P
I2P — еще одна анонимная одноранговая сеть, которая работает поверх обычного интернета. Она децентрализована, поэтому в ней нет серверов DNS, а их место занимают автоматически обновляемые «адресные книги». Роль адресов играют криптографические ключи, которые не выдают реальные компьютеры. Каждый пользователь проекта получает свой ключ, который невозможно отследить.
Подробнее о том, как устроены одноранговые сети, рассказывали в статье «Темный интернет, часть 1: что такое Dark Web и зачем его используют».
Сама сеть появилась в 2003 году в качестве opensource проекта. Сейчас это также полностью открытый проект, который развивают и поддерживают энтузиасты со всего мира.
Как работает I2P
В I2P все запросы зашифровываются на стороне отправителя и расшифровываются на стороне получателя с помощью алгоритмов NTCP2 и SSU. Это крипто-аналоги TCP и UDP, которые шифруют всю информацию, передаваемую роутеру.
Поэтому никто не может перехватить запросы. Даже промежуточный узел. Он не узнает, что произошло с запросом после него: обработал ли его следующий запрос или передал куда-то дальше.
I2P состоит из:
- Роутеров, которые имеют I2P-адреса и обычные IP. По сути, это транзитные узлы. Они все одинаковые и не отличаются друг от друга.
- Конечных точек — серверов или клиентов, реальное местоположение которых неизвестно.
- Туннелей — путей, по которым идет запрос и в которых собираются несколько роутеров.
Роутеры, транзитные узлы — часть цепочки серверов, которые формируют туннель для запроса. При этом никто не знает, какой запрос и в каком туннеле идет. Еще одна особенность — пользователь сам определяет точку назначения запроса, длину туннелей, а также их количество.
Туннель можно представить в виде обычного грузовика, который проезжает несколько блокпостов. Он не останавливается ни на одном из них и поэтому никто не знает, куда едет грузовик и что хранится в его кузове. При этом на машину могут смотреть все, а остановить — только блокпост-получатель.
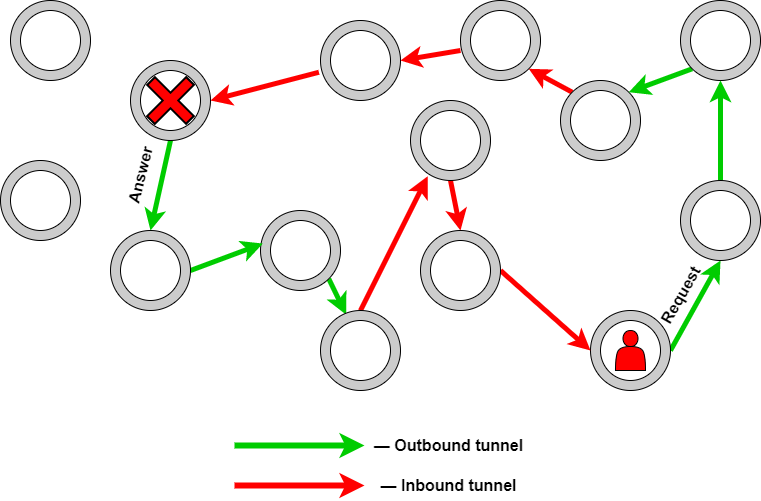
Конечные точки устроены сложнее. По сути, конечные точки — что-то вроде «сервера» для обычной сети. Т.е. к ней идут запросы как к роутеру. Но про то, что конкретная точка сети конечная, не знает никто. Также никто не знает, кому и какие данные предназначаются. Только конечная точка назначения может понять, что данные для нее. Поэтому вычислить нахождение «точки» нельзя.
Чтобы разобраться, введем два понятия — лизсет (LeaseSet) и флудфил (Floodfill или Routerinfo).
Лизсет — совокупность информации в I2P, которая содержит данные о входных туннелях, криптографических ключах и конечном адресе.
Флудфил — роутер, который выступает в роли справочной книги, хранит лизсеты и знает нужные места, которые ищет пользователь. А если не знает — перенаправляет в другую справочную службу.
Когда пользователь ищет что-то в I2P — запрашивает определенный лизсет у случайного флудфила.
Если флудфил не знает запрошенного адреса, дает адрес трех других флудфилов и запрос идет к ним. А те, в свою очередь, проверяют лизсеты в своей базе. И так до тех пор, пока нужный адрес не будет найден.
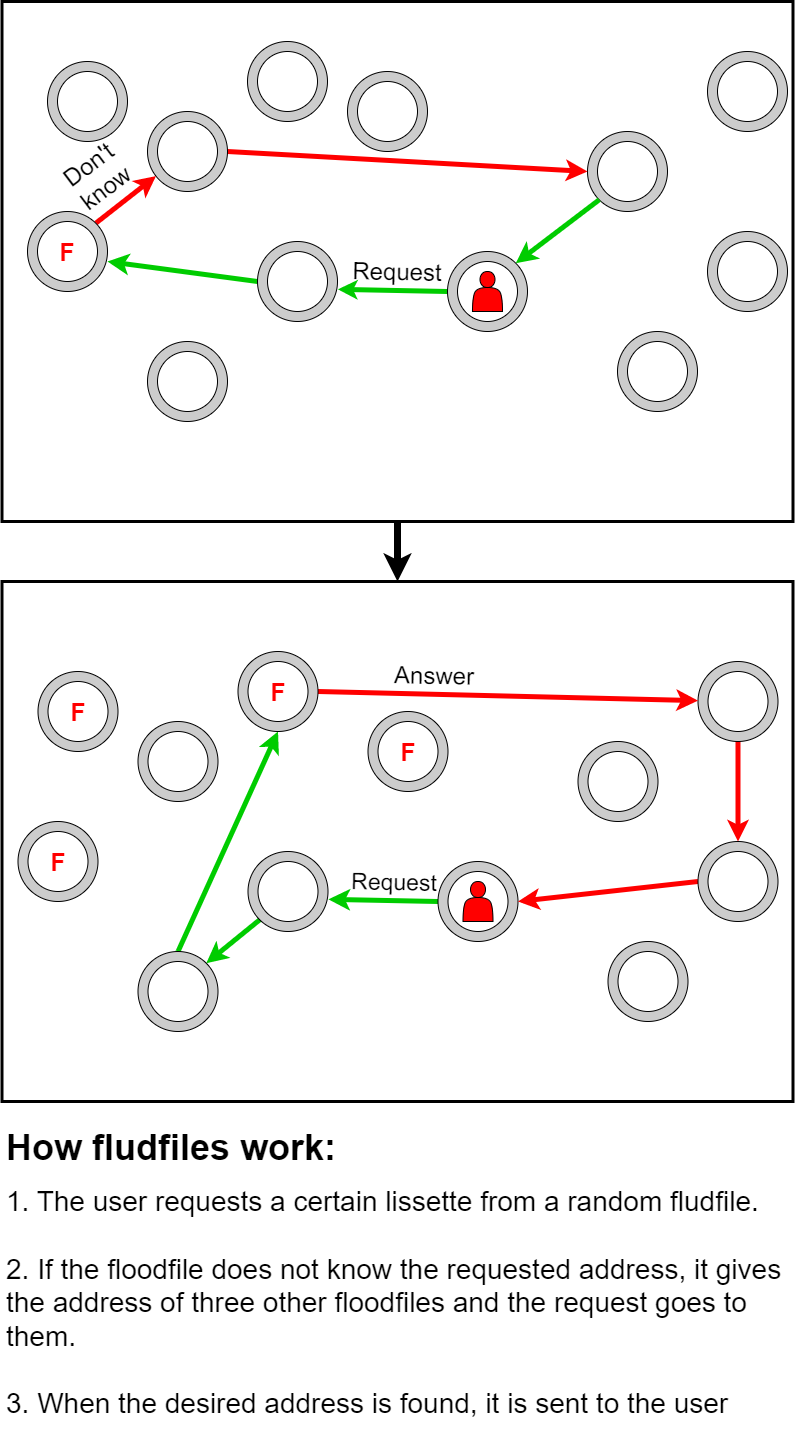
Нужный флудфил выбирается на основе целевого адреса и текущей даты. Из этой информации выводится хеш SHA256 — получаются данные длинной с обычный адрес.
Потом система ищет флудфил в локальной базе роутера и выбирает тот, который при операции «ИСКЛЮЧАЮЩЕЕ ИЛИ» с блоком «целевой адрес + дата» даст наименьшее число.
По сути, это функция обращения к флудфилу, которая помогает найти нужный адрес. Вот только адрес генерируется случайный, поэтому флудфил сообщает адреса трех соседей, к которым мы обращаемся в поиске нужного адреса. А сам алгоритм выбора флудфила с датой нужен для рандомизации обращений. Так каждый запрос на новый адрес пройдет через новый флудфил и они будут меняться каждый день.
Активный узел сети имеет в своей базе в среднем 5000 активных роутеров и принимает сотни, а то и тысячи абсолютно случайных транзитных подключений.
Он даже может отказаться от туннелей и обращаться к узлу напрямую. И, хотя узел не узнает, что к нему обращаются без туннелей и не узнает всю длину цепочки, анонимность отправителя все равно пострадает. Ведь без туннелей перехватить запрос все еще сложно, но возможно.
Кроме этого, каждый транзитный узел периодически опрашивает случайный флудфил и получает в ответ адреса трех новых транзитных узлов. Так увеличивается сеть и находятся новые флудфилы. Каждый активный узел I2P имеет в своей базе в среднем 5000 активных роутеров и принимает сотни, а то и тысячи абсолютно случайных транзитных подключений.
Благодаря этому через роутеры проходит много транзитного трафика — создается «белый шум». Поэтому вычислить среди множества информации какую-то определенную практически невозможно.
А в качестве адресов конечных точек в I2P работают идентификаторы, которые выводятся из открытого ключа подписи. Хеш-сумма вычисляет уникальную строку определенной длины и в конце добавляет псевдодомен «.b32.i2p» — так получается привычный внутрисетевой адрес.
Дальше к внутрисетевому адресу привязывается обычный читаемый домен.
Туннели формируют путь через выбранный список маршрутизаторов. Они защищены многоуровневым шифрованием, а каждый из маршрутизаторов на пути может расшифровать только один слой. Расшифрованная информация содержит IP следующего маршрутизатора и следующий уровень зашифрованной информации, которая уйдет к следующему роутеру.
Информация по туннелям идет в одну сторону и каждый туннель имеет начальную и конечную точки. Чтобы получить обратное сообщение, требуется еще один туннель.
Работают туннели так: сначала строится исходящий туннель, который состоит из нескольких узлов. Каждый узел расшифровывает часть информации, в которой содержатся инструкции. Они сообщают, на какой узел передавать информацию дальше.
В последней точке исходящего туннеля узел расшифровывает часть информации в которой сказано о завершении построения цепочки.
А так как все цепочки однонаправлены, последнему узлу сообщается маршрут входного туннеля. В результате информация возвращается к пользователю.
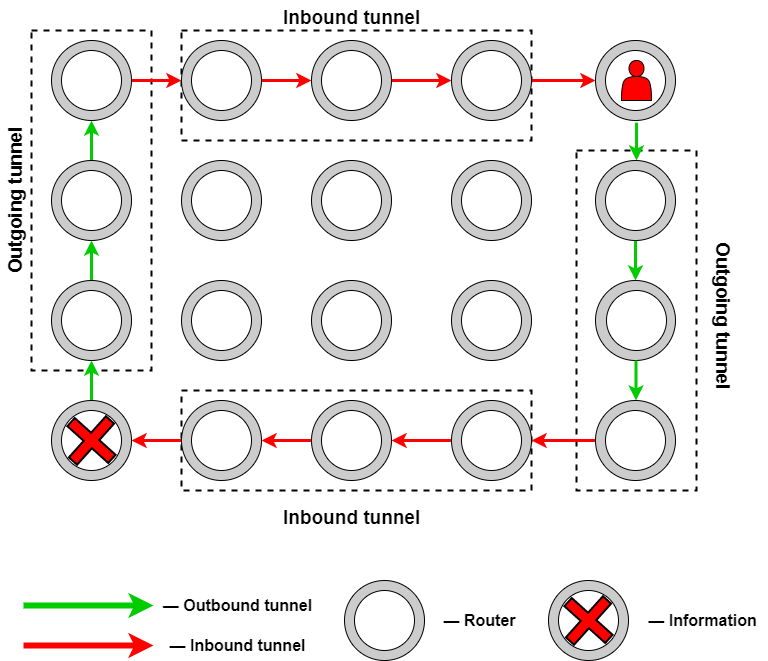
В зависимости от типа туннеля — входящего или исходящего — последний узел называется Endpoint или Gateway. Endpoint означает конечную точку, а Gateway — входные ворота. Задача endpoint — собрать информацию по частям в более большой пакет данных и переслать через Gateway нужному пользователю.
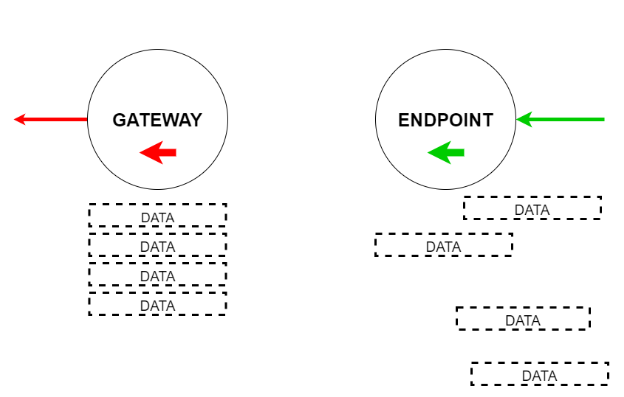
Например, Богдан передает данные Ибрагиму. Для передачи данных Богдан строит выходной тоннель из 4 узлов. А Ибрагим строит входной на 5 узлов. Когда Богдан отправляет информацию, она сначала идет по выходному тоннелю к Endpoint через его 4 узла, а потом оттуда выходит через Gateway и идет через 5 входных узлов Ибрагима.
Если Ибрагим решит ответить, то построится новый путь. А количество узлов будет зависеть от желания Богдана и Ибрагима.
Сама сеть I2P работает при помощи чесночной маршрутизации.
Как работает чесночная маршрутизация
Чесночную маршрутизацию разработали около 20 лет назад. Это метод построения туннелей для передачи информации, в котором несколько сообщений зашифрованы и собраны в один запрос.
Чесночную маршрутизацию называют продвинутой версией луковичной маршрутизации, которую использует сеть Tor. Ее используют, когда нужно отправить зашифрованное сообщение через транзитные узлы, скрыв содержимое от них.
Главное отличие двух методов маршрутизации — в чесночной могут шифроваться одновременно несколько сообщений в разных зубчиках, а в луковичной — одно.
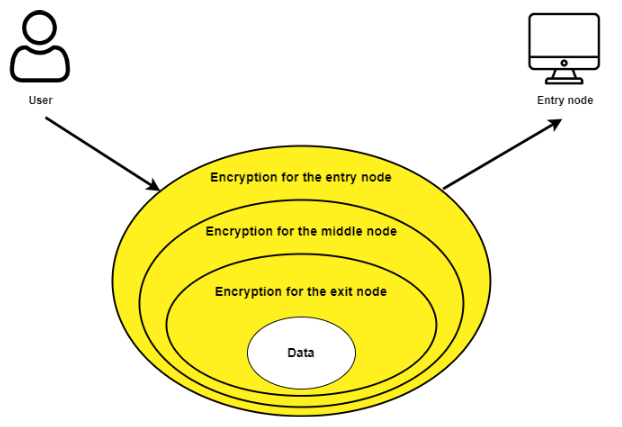
А при передаче сообщения с чесночным маршрутизатором, оно шифруется и расшифровывается при взаимодействии с каждым узлом. При этом на этапе создания пути каждому узлу предоставляются только инструкции маршрутизации для следующего перехода.
Во время прохождения самого запроса сообщение передается через туннель и доступно только его конечной точке.
Чеснок в I2P — это блок информации, который состоит из нескольких зубчиков. Часть из них — нужные сообщения для пользователя, другая часть — транзитные сообщения.
Например, когда пользователь хочет отправить информацию другому человеку, она оборачивается в зубчик, который потом добавляется к другим блокам информации от других участников сети — формируется чеснок. Чеснок шифруется специальным алгоритмами и передается на разные узлы сети.
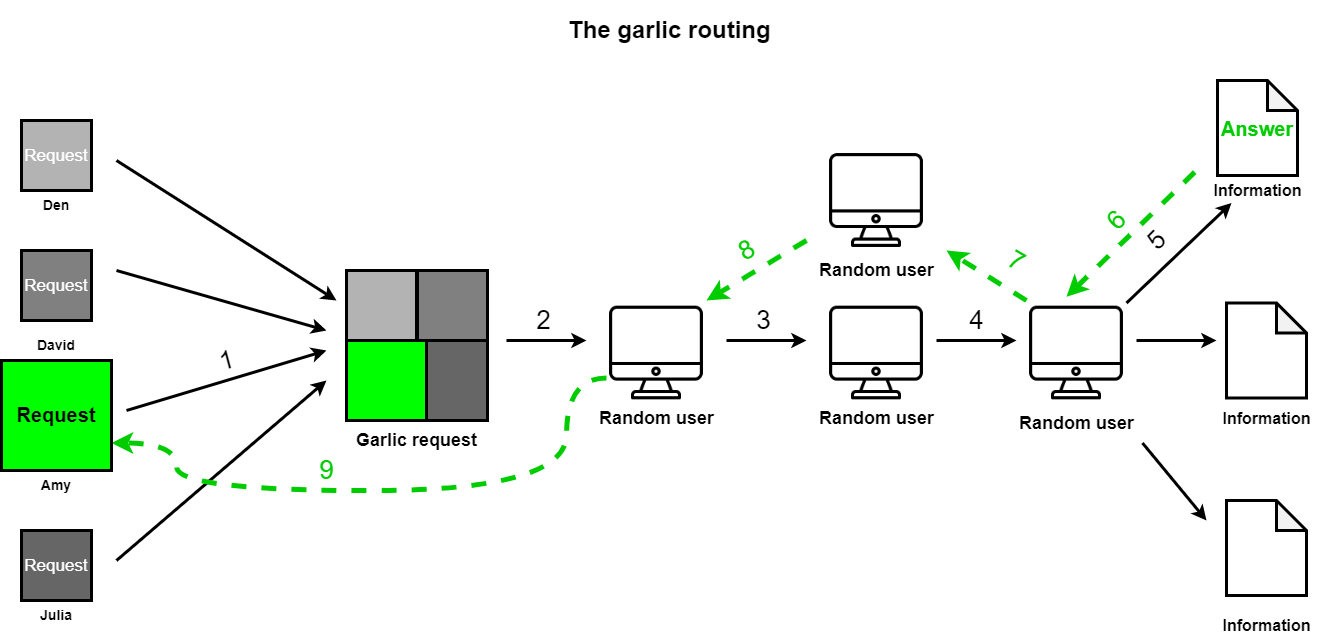

В каждый чеснок входит информация для создателя каждого зубчика:
- Номер туннеля на его роутере — случайные 4 байта информации.
- Адрес следующего роутера и номер туннеля на нем.
- Ключ симметричного шифрования и ключ шифрования вектора инициализации. Вектор инициализации — случайная или псевдослучайная последовательность символов, которая добавляется к ключу шифрования и повышает его безопасность.
- Роль узла в цепочке: транзитный или конечный.
Каждый зубчик опознается по первым байтам информации, которая в нем содержится — это часть хеша его адреса. Когда получатель находит нужный зубчик — расшифровывает содержимое с помощью криптографического ключа. Информацию из других зубчиков расшифровать не получится, потому что она предназначена для других получателей и защищена другими ключами.
Подытожим: как происходит взаимодействие запроса и сети
Сначала пользователь создает запрос и для него формируются туннели. Запрос идет по входному туннелю через несколько транзитных точек и приходит на конечные точки → запрашивает лизсеты у случайных флудфилов.
Транзитные точки используются для того, чтобы никто не смог отследить местоположение конечной точки.
Вместе с запросом к конечной точке приходят данные входного туннеля. Они нужны для того, чтобы запрос с ответом мог вернуться обратно к пользователю.
Когда запрос приходит на сервер, тот формирует ответ и отправляет его пользователю. Так как туннели в I2P однонаправленные, сервер отправляет ответ по своему исходящему туннелю. А адрес получателя — входной туннель, по которому изначально пришел запрос на сервер.
Вот как это выглядит на общей схеме.
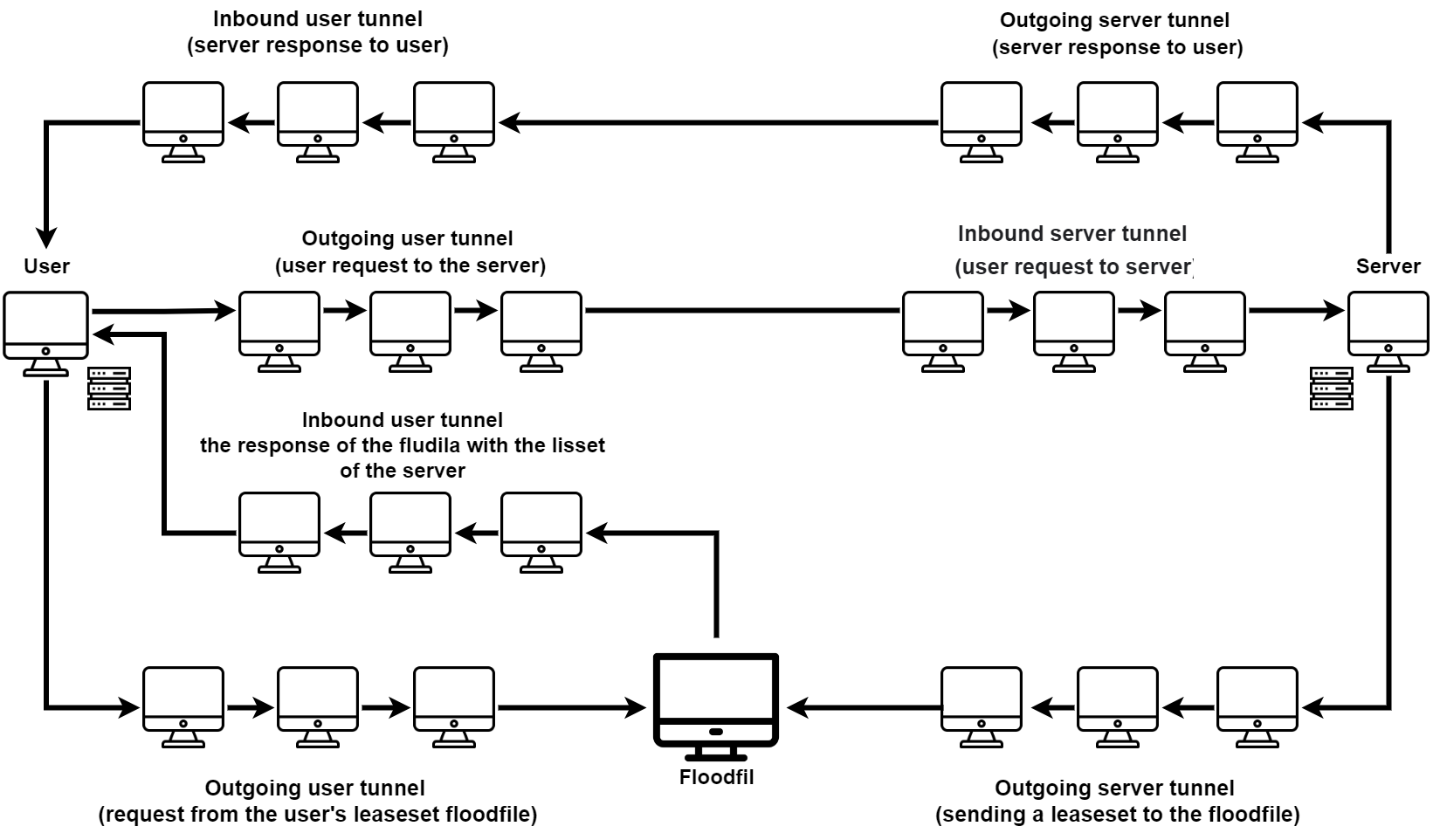
Получилось сложно и запутанно, давайте рассмотрим все пошагово.

Первый шаг — сервер публикует свой лизсет на флудфиле. Для этого он отправляет его по исходящему туннелю.
Второй шаг — пользователь хочет подключиться к этому серверу. Для этого он отправляет запрос по своей исходящему туннелю на флудфил.
Третий шаг— флудфил отправляет ответ на компьютер человека по входящему туннелю пользователя.
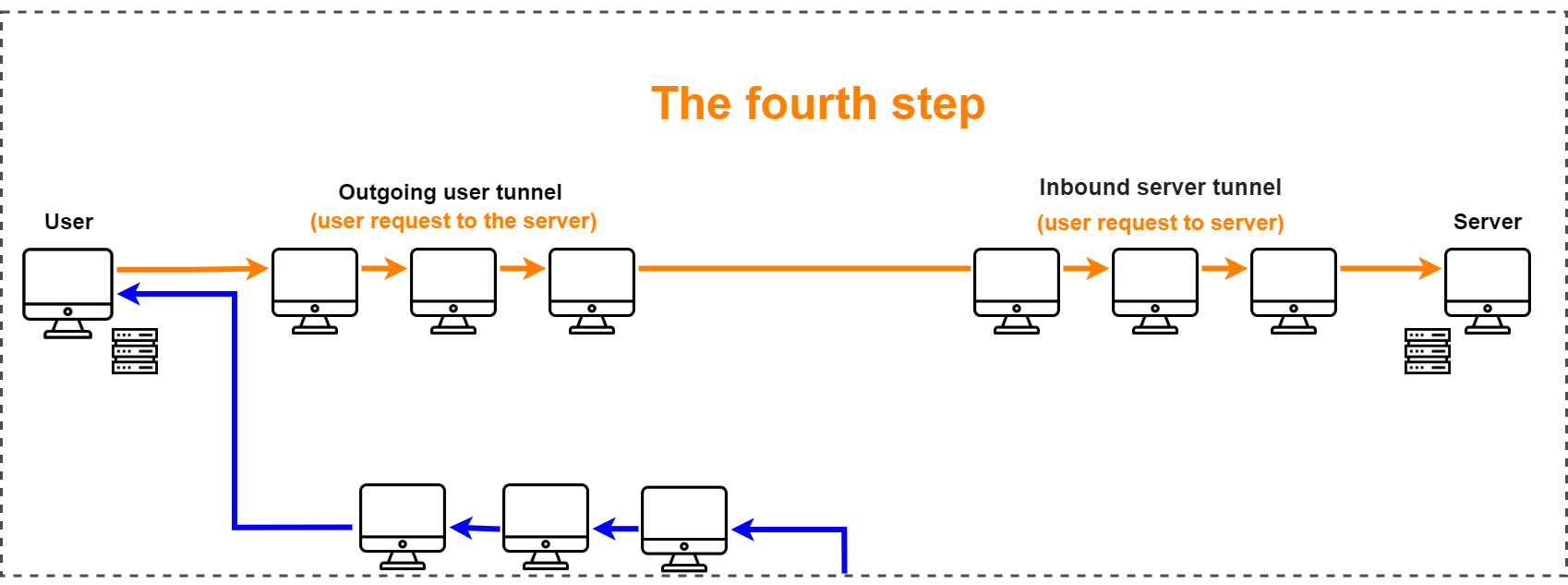
Четвертый шаг — пользователь отправляет запрос на сервер. Сначала запрос идет по исходящему туннелю пользователя и попадает во входящий туннель сервера.
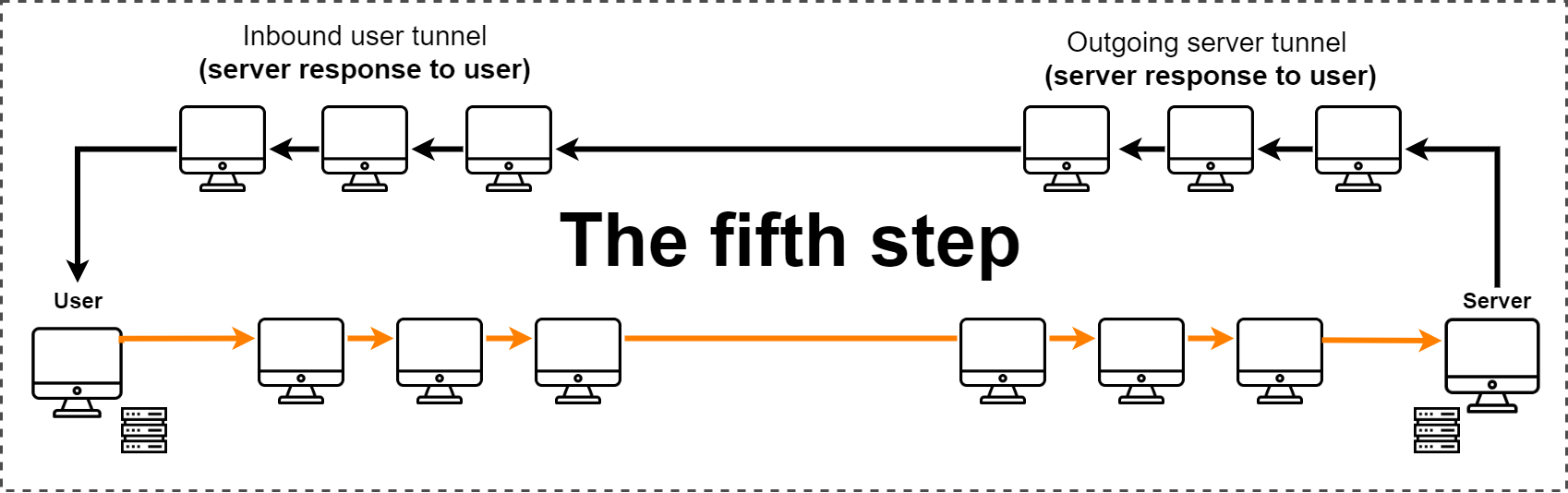
Пятый шаг — сервер отвечает пользователю. Он отправляет ответ по исходящему туннелю сервера, который потом попадает во входящий туннель пользователя и оказывается на ПК человека. После этого у человека открывается нужный ресурс.
Через какие клиенты работает I2P
I2P-сеть построена на двух технологиях: Java и C++. Изначально проект создали на Java и назвали его I2P, а в 2013 году энтузиаст с ником Original создал I2P-клиент на языке C++ и назвал его I2Pd. И он намного лучше предшественника. Объясняем, почему.
I2Pd архитектурно превосходит версию на Java. Дело в том, что I2P содержит массу криптографии, реализовывать которую через Java очень сложно из-за жутких тормозов. Эту проблему пытались решить и добавили в Джава-роутер библиотеки, написанные на языке С. И каждый вызов этих библиотек — большие накладные расходы.
А в C++ вся криптография встроена в сеть и работает нативно — не загружает сеть.
Кроме быстрой работы сети, роутеры в I2Pd потребляют меньше системных ресурсов. Потому что программа на C++ напрямую взаимодействует с системой. А в Java-версии все работает внутри виртуальной машины, которая выступает в роли прослойки между операционной системой и программным обеспечением.
Еще одно преимущество I2Pd — быстрая скорость. В обычном I2P соединение идет через несколько Java-роутеров, из-за чего запрос обрабатывается дольше и скорость интернета не превышает несколько десятков килобит в секунду. В C++ запросы обрабатываются быстрее, поэтому скорость соединения может доходить до одного мегабита в секунду.
Чем I2P отличается от Tor
Одно из главных отличий двух сетей — Tor является сетью клиентов, а I2P — серверов. Дело в том, что задача Tor — скрыть IP-адрес клиента, который сделал запрос. А задача I2P — скрыть сервер, к которому идет запрос от пользователя. Но есть и другие отличия:
- Туннели в I2P однонаправленные, в Tor — идут в обе стороны. То есть в I2P трафик идет по одному туннелю к получателю, а возвращается к отправителю по другому.
- Tor использует луковичное шифрование, а I2P — чесночное. Оба вида шифрования надежные, но в луковичном трафик защищается послойно, а в чесночном — еще и по блокам для каждого получателя. То есть конечный уровень защиты в чесночном шифровании выше.
- В I2P никто из участников сети не знает, кто отправитель, а кто — получатель. А в Tor есть промежуточный узел, который знает, откуда идет файл и куда его нужно отправить.
- Если Tor забанен в вашей стране, то подключиться к нему будет проблематично. Он не сможет найти входные узлы, чтобы построить сеть и понять, кому отправлять сообщение.
А в I2P даже если забанят один флудфил, можно самостоятельно задать другой и так получить список входных точек сети. Во второй раз задавать ничего не придется — входные точки сети уже будут известны и ПО будет их использовать. Получается, отказоустойчивость в I2P выше, чем в Tor.
- Tor подходит не только для входа в даркнет, но и для использования обычного интернета. Например, через Tor можно заходить в обычные соцсети или пользоваться стриминговыми сервисами. А I2P предназначен только для обмена сообщениями в своей сети, хотя в I2Pd есть почти все возможности обычного интернета.
- I2P — изначально opensource проект, который развивают энтузиасты. Их цель — создать анонимный и безопасный интернет. А сеть Tor изначально придумало правительство и сейчас оно может идентифицировать конкретного пользователя.
Например, В 2016 году США внесли поправки в правило 41. Это дало право ФБР массово взламывать любое количество компьютеров в любой точке мира, используя один ордер. Поэтому правоохранительные органы получат право взломать узел и узнать вашу конфиденциальную информацию. Такой случай произошел в 2016 году. Тогда ФБР взломали 8 000 компьютеров в 120 странах.